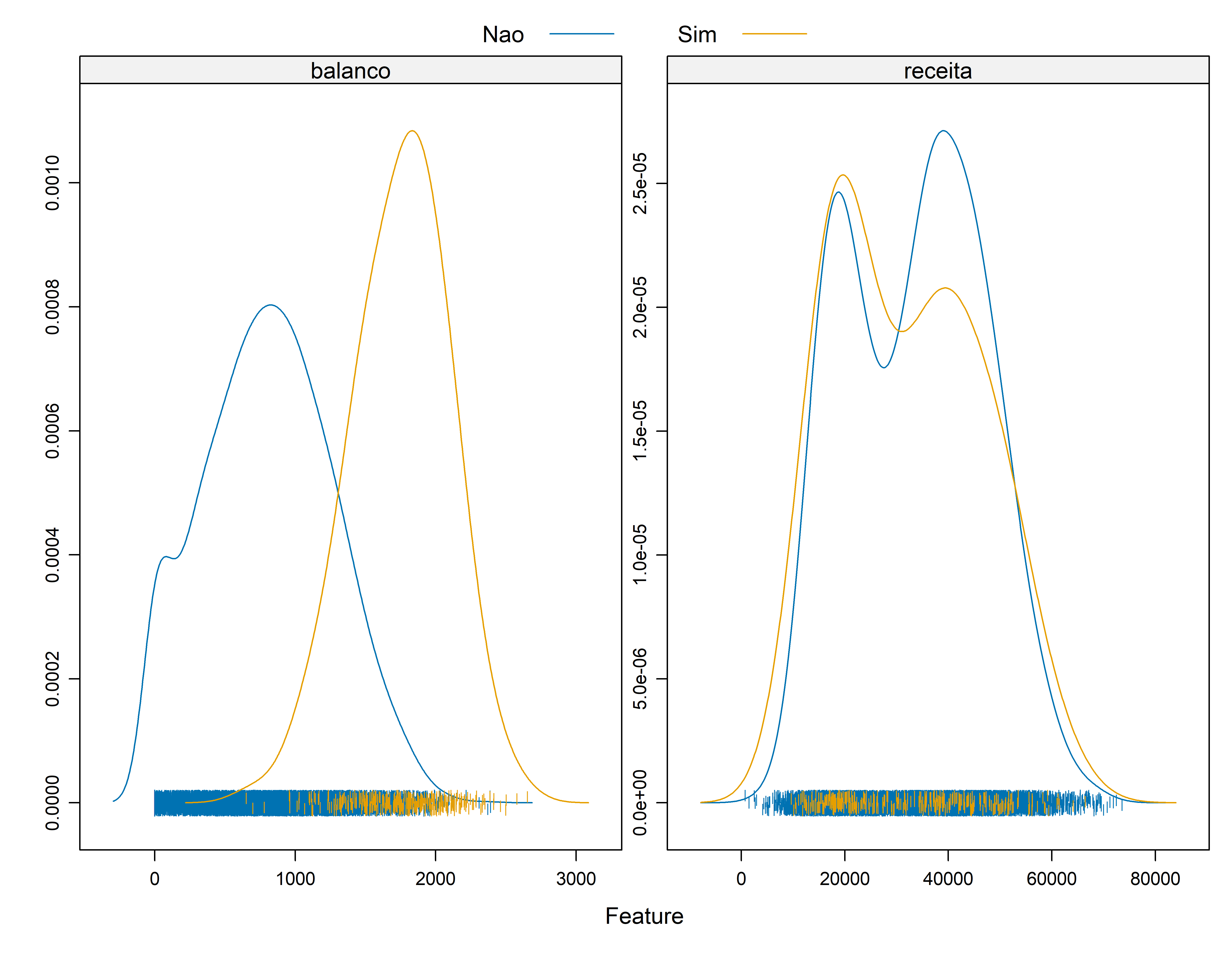
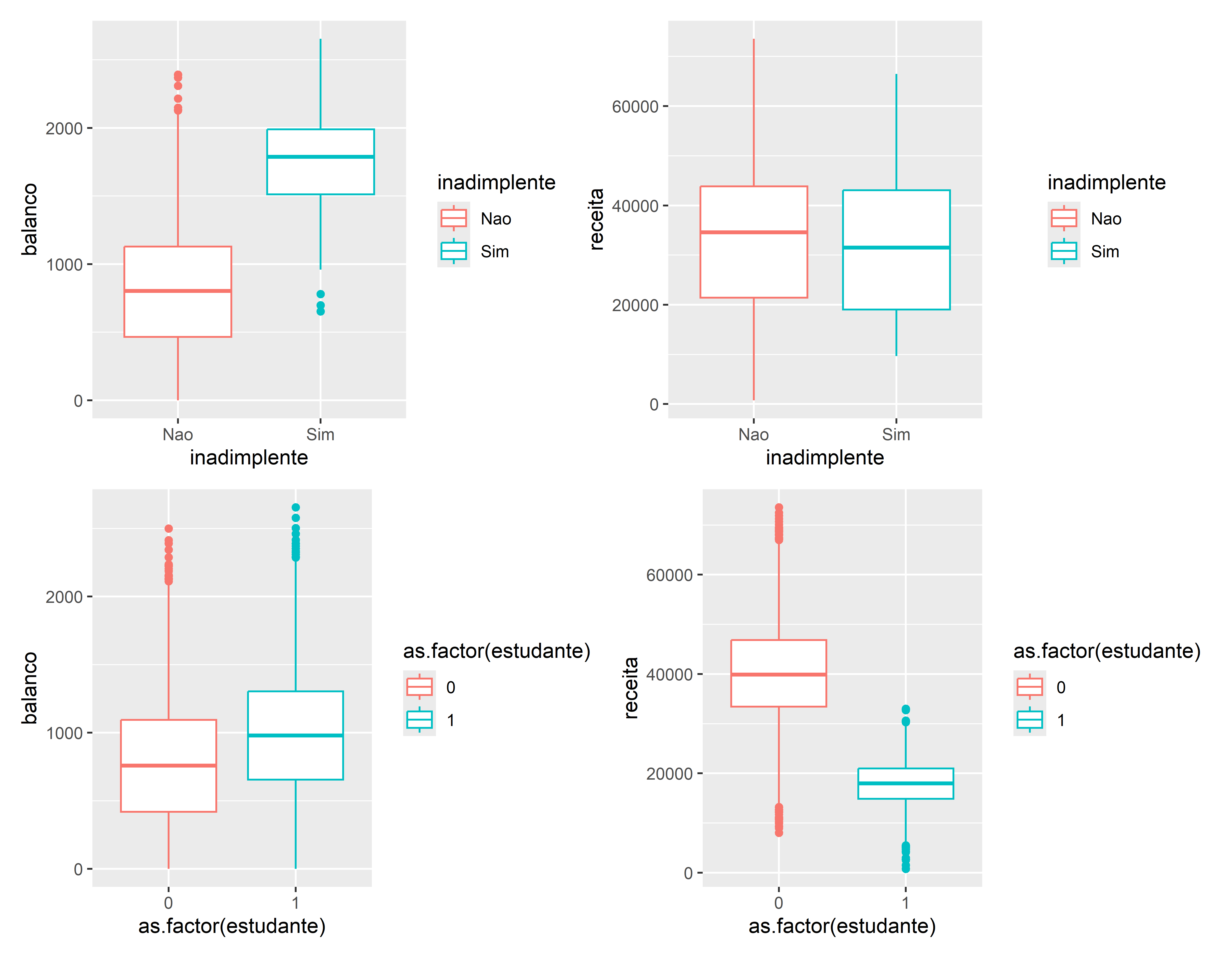
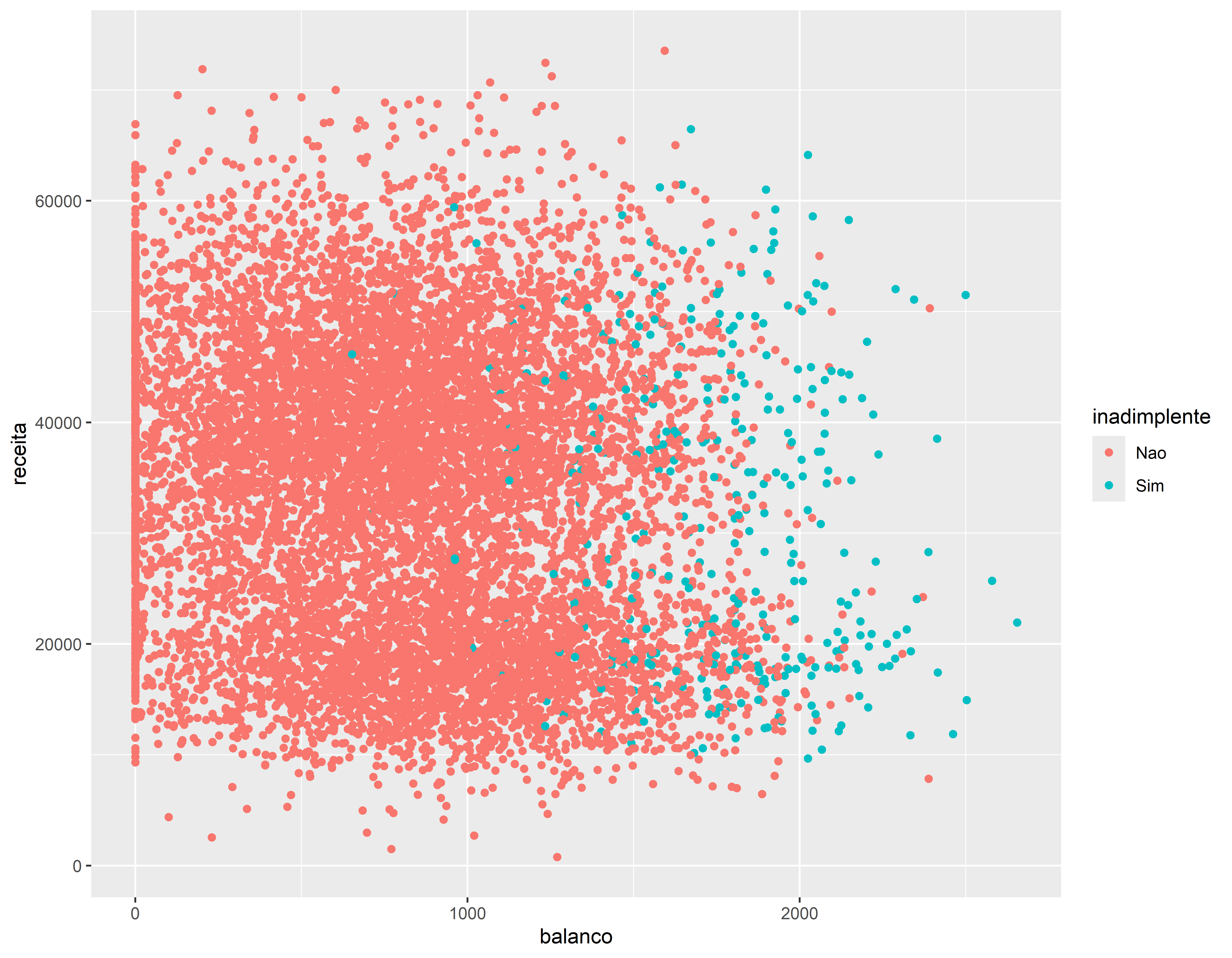
O KNN é um algoritmo muito simples no qual cada observação é prevista com base em sua “semelhança” com outras observações. Ao contrário da maioria dos métodos, KNN é um algoritmo baseado na memória e não pode ser resumido por um modelo de forma fechada. Isso significa que as amostras de treinamento são necessárias no tempo de execução e as previsões são feitas diretamente das relações amostrais. Consequentemente, os KNNs também são conhecidos como aprendizes preguiçosos
#> default student balance income
#> 1 No No 729.5265 44361.625
#> 2 No Yes 817.1804 12106.135
#> 3 No No 1073.5492 31767.139
#> 4 No No 529.2506 35704.494
#> 5 No No 785.6559 38463.496
#> 6 No Yes 919.5885 7491.559
ggplot(data =credito, aes(x=balanco, y =receita, col =inadimplente))+geom_point()
KNN
Vamos usar a função knn da biblioteca caret que tem ótimas funcionalidades. Observem que a saída pode ser as classes ou as probabilidades de pertencer a uma classe
Como o KNN usa as distancias entre os pontos ele é afetado pela escala dos dados, portanto, é necessário que os dados sejam normalizados (padronizados) para eliminar este efeito.
Quando temos diversas variáveis explicativas em diferentes escalas, em geral, elas devem ser transformadas para ter media zero e desvio padrão 1
Criando conjuntos de treino e teste e normalizando variáveis
set.seed(2025)y<-credito$inadimplentecredito_split<-createDataPartition(y, times =1, p =0.10, list =FALSE)conj_treino<-credito[-credito_split,]conj_treino[,3:4]<-scale(conj_treino[,3:4])# scale normalizaconj_teste<-credito[credito_split,]conj_teste[,3:4]<-scale(conj_teste[, 3:4])summary(conj_treino)
#> inadimplente estudante balanco receita
#> Nao:8700 Min. :0.0000 Min. :-1.73003 Min. :-2.4534
#> Sim: 299 1st Qu.:0.0000 1st Qu.:-0.72954 1st Qu.:-0.9140
#> Median :0.0000 Median :-0.03104 Median : 0.0764
#> Mean :0.2946 Mean : 0.00000 Mean : 0.0000
#> 3rd Qu.:1.0000 3rd Qu.: 0.68437 3rd Qu.: 0.7707
#> Max. :1.0000 Max. : 3.76117 Max. : 2.9933
#> inadimplente estudante balanco receita
#> Nao:967 Min. :0.0000 Min. :-1.69940 Min. :-2.12069
#> Sim: 34 1st Qu.:0.0000 1st Qu.:-0.76771 1st Qu.:-0.90454
#> Median :0.0000 Median : 0.02552 Median : 0.06997
#> Mean :0.2927 Mean : 0.00000 Mean : 0.00000
#> 3rd Qu.:1.0000 3rd Qu.: 0.67537 3rd Qu.: 0.73936
#> Max. :1.0000 Max. : 2.86197 Max. : 2.86471
1a Modelo
Vamos usar a regra da raiz quadrada do tamanho da amostra para definir o número de vizinhos do KNN.
k<-round(sqrt(nrow(conj_treino)),0)# número de vizinhosk
#> [1] 95
set.seed(2025)t_knn1<-knn3(inadimplente~balanco+receita+estudante, data =conj_treino, k =k)t_knn1
#> 95-nearest neighbor model
#> Training set outcome distribution:
#>
#> Nao Sim
#> 8700 299
Avaliando o modelo
Através da função matriz de confusão do pacote caret conseguimos obter as principais medidas de avaliação de um modelo de classificação.
Veja que a acurácia deu um valor alto, mas isto não é suficiente para considerarmos que temos um bom modelo. Veja que a sensibilidade está muito baixa e que o ideal é que tenhamos valores altos de sensibilidade e especificidade.
Observar que a prevalência é muito baixa o que está afetando os resultados do modelo.
y_chapeu_knn1<-predict(t_knn1, conj_teste, type ="class")confusionMatrix(y_chapeu_knn1, conj_teste$inadimplente, positive="Sim")
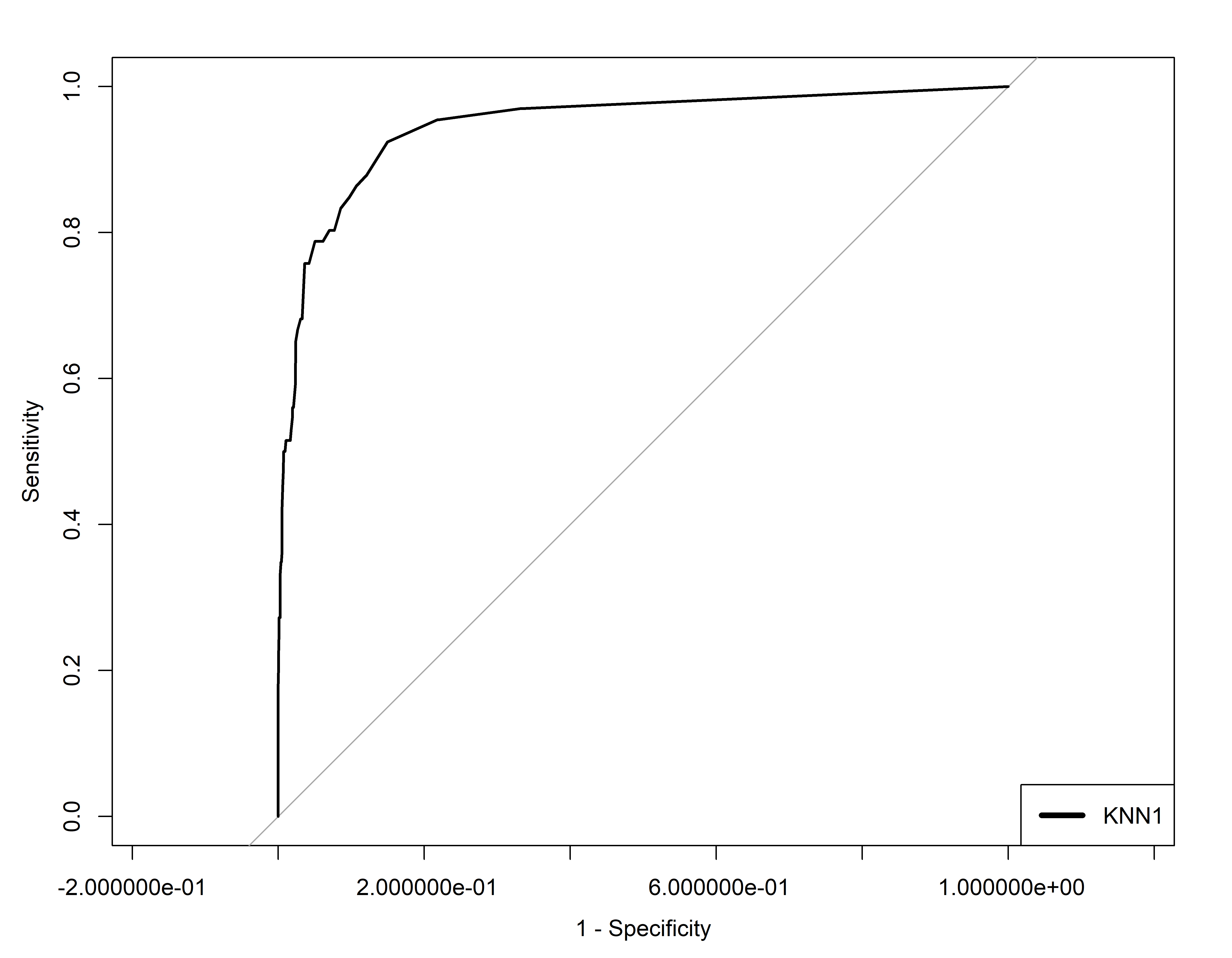
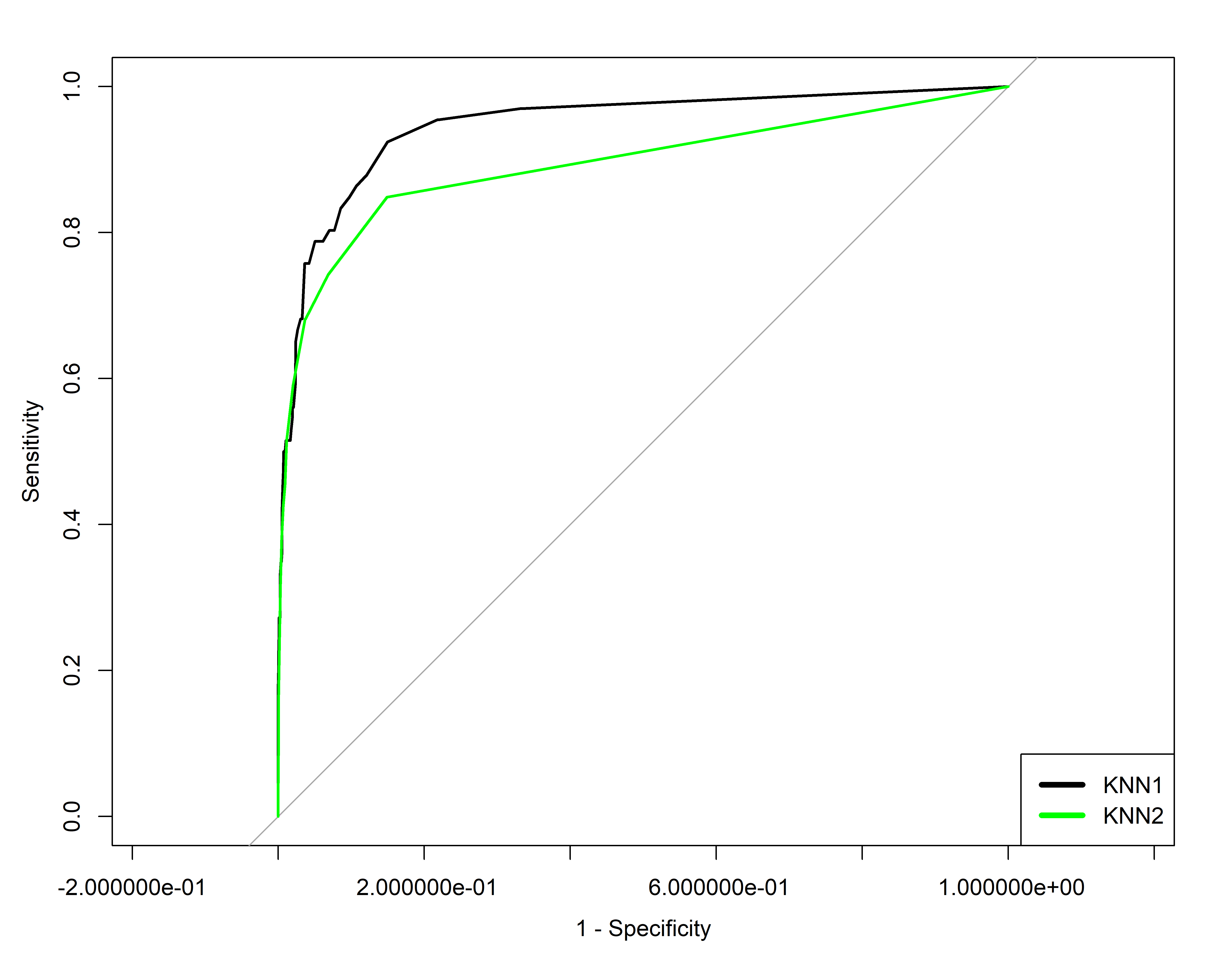
# Aqui gera o curva e salvo numa variávelroc_knn1<-roc(conj_teste$inadimplente~p_chapeu_knn1[,2], plot =FALSE, print.auc=FALSE)# Visualização com ggrocggroc(roc_knn1)+ggplot2::labs(title ="ROC - KNN", x ="1 - Especificidade", y ="Sensibilidade")+ggplot2::theme_minimal()
Area embaixo da curva ROC
# Area abaixo da Curva (AUC)as.numeric(roc_knn1$auc)
#> [1] 0.9191405
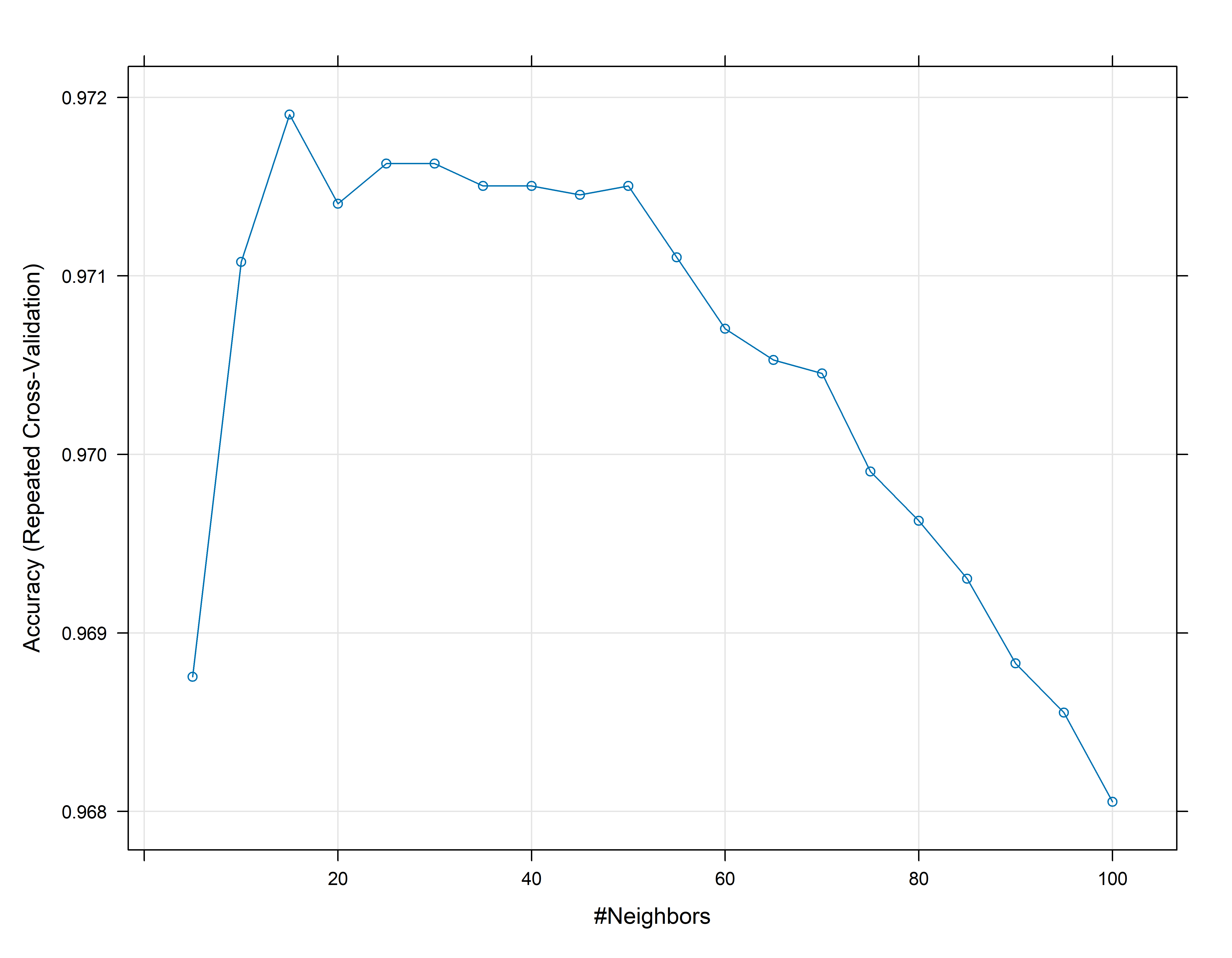
Variando K
Anteriormente usamos k=95 . Este parametro, em geral, deve ser ajustado para melhoramos os modelo KNN. Para isto vamos usar a função train da biblioteca caret
Observe que a otimização de k, no exemplo abaixo, é feita através de acurácia. O k também pode ser otimizado usando o valor do AUC (área embaixo da curva ROC).
set.seed(2025)# Usando validação cruzada para obter o valor de k através da função train da biblioteca caret e o controle do treino e fazendo um gride de valores para k.ctrl<-trainControl(method ="repeatedcv", number =5, repeats =5)t_knn2<-train(inadimplente~balanco+receita+estudante, method ="knn", trControl=ctrl, tuneGrid =data.frame(k =seq(5,150, by=5)), metric ="Accuracy", data =conj_treino)## Resultados do treinot_knn2
#> k-Nearest Neighbors
#>
#> 8999 samples
#> 3 predictor
#> 2 classes: 'Nao', 'Sim'
#>
#> No pre-processing
#> Resampling: Cross-Validated (5 fold, repeated 5 times)
#> Summary of sample sizes: 7199, 7199, 7199, 7199, 7200, 7199, ...
#> Resampling results across tuning parameters:
#>
#> k Accuracy Kappa
#> 5 0.9704413 0.42266071
#> 10 0.9716414 0.41185688
#> 15 0.9723526 0.41049306
#> 20 0.9730415 0.41527673
#> 25 0.9729749 0.39961432
#> 30 0.9729305 0.39434063
#> 35 0.9725527 0.37664935
#> 40 0.9724415 0.36463583
#> 45 0.9723749 0.35587285
#> 50 0.9722193 0.34677085
#> 55 0.9722415 0.34231099
#> 60 0.9719303 0.32682892
#> 65 0.9717303 0.31692192
#> 70 0.9715748 0.30754847
#> 75 0.9709079 0.27742350
#> 80 0.9706412 0.25982263
#> 85 0.9703523 0.24349134
#> 90 0.9702412 0.23166492
#> 95 0.9697301 0.20218244
#> 100 0.9690410 0.16434426
#> 105 0.9686633 0.13872824
#> 110 0.9683299 0.11503994
#> 115 0.9678409 0.07816959
#> 120 0.9676187 0.05780951
#> 125 0.9673964 0.04083628
#> 130 0.9672408 0.02760184
#> 135 0.9671297 0.02148245
#> 140 0.9670853 0.01773521
#> 145 0.9669741 0.01144419
#> 150 0.9669741 0.01144419
#>
#> Accuracy was used to select the optimal model using the largest value.
#> The final value used for the model was k = 20.
Observe que os resultados de área abaixo da ROC não são suficientes para a escolha do k, pois precisamos estar atentos ao valores de sensibilidade e especificidade! A depender da importância de cada um destes valores para o problema em questão, podemos escolher um k que nos dê um bom equilíbrio entre estes dois valores.